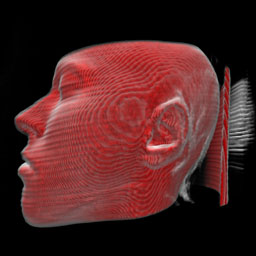
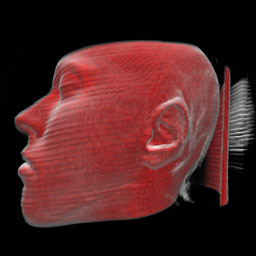
The render mode compositing implements the direct volume rendering technique presented by [Levoy87]. For the classification both transfer functions (for density values and for gradient magnitude values) can be used. The step size defines in which intervals the volume is sampled during raycasting.
The color and the opacity are accumulated in front-to-back order. The current color is multiplied with the current opacity and with one minus the total opacity of already rendered sample points.
Depth cueing is implemented as described in [Levoy87]: lightcolor / (k1 + k2*distance). The first value defines the part independent from the distance to the image plane, whereas the second value is multiplied with the distance of a voxel to the image plane. From this it follows, that more distant voxels are rendered with a lower intensity than the ones close to the image plane.
| |
|
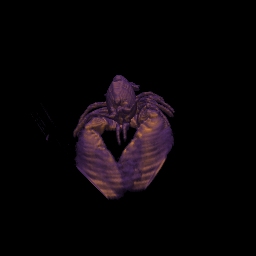
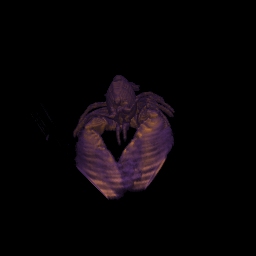
Woodgrain artifacts can be removed with stochastic jittering. For each ray the start position is moved a little bit by a value gained from a noise texture in the view direction. The offset ranges from zero to a half sampling step (forward or backward) and is multiplied with the value defined in the field Stochastic jittering. Hence, when the value for stochastic jittering is set to zero, the volume is sampled at regular intervals.
The result may look worse with stochastic jittering, but often the introduced noise is better than the regular patterns. The left image shows a rendering without jittering and the right image shows the same rendering with jittering set to one.
 |
 |