Visualisierung 2
– Dokumentation
Gruppe: ImageVis (Bernhard Vorderegger)
Thema: Visual
analysis of controversy in user-generated encyclopedias.
1
Inhaltsverzeichnis
1.1.2 Richtung der Revision Kanten
1.1.3 Regelmäßige Änderungen durch Autoren
1.1.1 Positionen der
Autorknoten
1.4 Graphical User
Interface(GUI)
2 Einleitung
Das
gewählte Paper [BL] behandelt die Visualisierung der Änderungshistorie von
Wikipedia-Seiten.
Dieser Aspekt ist besonders relevant, da die Seiten durch die Community
erstellt werden.
Die resultierende Version wird durch Review, Diskussion und Verbesserung
generiert.
Das Paper stellt Techniken vor, um dominante Autoren, deren Rolle und die
Änderungen zu visualisieren.
Anhand der Versionshistorie einer Wikipedia Seite wird ein Revision Netzwerk
generiert.
Das
Revision Netzwerk basiert auf Metadaten der Version.
Die Änderungen werden nicht inhaltsbezogen analysiert, das heißt die Technik
ist sprachunabhängig.
Zusätzlich wird die Rolle des Autoren sowie Muster der Konfrontation
dargestellt.
1.1 Revision
Netzwerk
Wikipedia
liefert die Versionhistorydaten im XML Format. Diese Daten enthalten Timestamp,
Author ID, ..
Die
Revisionsdaten werden in einen gewichteten Graphen umgewandelt.
Die Autoren sind die Knoten. Die Gewichte der Knoten werden anhand der
Revisionen ermittelt.
Dabei
wird für den Autor der Version ri und dem Autor der Version ri-1 das Gewicht für die Verbindung
aus dem
Verhältnis
von der Zeit zwischen den beiden Versionen und der durchschnittlichen
Änderungszeit berechnet.
Liegt die Änderungszeit über der Durchschnittszeit wird keine Verbindung eingetragen.
Die Verbindung zwischen den Autoren wird durch die chronologischen
Veränderungen ermittelt,
nicht
aus den inhaltlichen Zusammenhängen!
1.2 Visual
Analysis
Die
Position der Knoten in der 2D Darstellung werden durch ein Minimierungsproblem
gelöst.
Dabei wird der maximale Abstand zwischen Knoten mit Revision-Interaktionen
ermittelt.
Die Positionen werden normalisiert, so dass eine elliptische Anordnung der
Knoten entsteht (Bild 2).
Für
die Autoren werden zusätzliche folgende Eigenschaften ermittelt.
1.1.1
Revisor Eigenschaften
Der
Grad der ausgehenden Kanten steht für die Anzahl der Verbindungen in dem der
Autor als Revisor auftritt.
Die eingehenden Kanten stehen für die Verbindungen bei denen der Autor
verbessert wird.
Das
Verhältnis wird je Autor durch eine Ellipse in der Darstellung des Knoten
abgebildet.
1.1.2
Richtung der Revision Kanten
Die Kanten
werden mit einer Richtungsinformation versehen.
Die Breite der Linie entspricht dem Gewicht. Die Richtungsinformation wird
durch einen Gradienten Verlauf
der
Farbe dargestellt.
1.1.3
Regelmäßige
Änderungen durch Autoren
Je
Autor wird die Änderungsaktivität je Wochenintervall ermittelt. Diese
Information wird als Knotenfarbe abgebildet.
Die
Aktivität aller Autoren wird als Balkendiagramm dargestellt.
1.3 Filterfunktionen
Die
Inputdaten können für ein bestimmtes Zeitintervall ausgewählt werden.
Erweiternd
wird eine Einschränkung auf relevante Subnetze umgesetzt, dies wird durch
eine
Spectral Graph Clustering Heuristik erreicht.
3
Implementierungsdetails
Die
Implementierungsdetails geben einen Überblick über die Komponenten und deren
Funktionen.
1.1
Komonentenübersicht
Die Webanwendung ist im Kontext eines Web-Containers
implementiert und basiert auf Basis von Java Server Pages (JSP) sowie einem
d3js SVG Frontend mit einer
JSON Rest Datenanbindung. Die grün dargestellten Komponenten sind die Java
Klassen mit den zentralen Funktionen die in den folgenden Sektionen beschrieben
werden.

Bild 1 Komponenten
1.2 Datenquelle
Die
Daten können von Wikipedia im XML Format geladen werden (Wikipedia Special:Export
Webservice). Eine Dokumenttypdefinition (DTD) wird ebenfalls angeboten.
Aus den DTD Daten wurden mit dem Java XJC Tool die Java Mapping Sourcen
generiert.
Die
Funktion ist in der Klasse wiki.WikiDataProcessor implementiert. Die
Webservicedaten werden, um bei einem nicht verfügbaren Wiki Service abrufbar zu
sein, als
xml-Files
gespeichert.
1.3
Berechnungen
1.1.1
Positionen
der Autorknoten
Die
chronologischen Änderungen werden in eine Adjazenzmatrix übersetzt. Wobei nur jene
Autorensequenz verwendet wird deren zeitlicher Abstand unterhalb der
Durchschnittsänderungszeit
liegt.
Um den
Abstand zwischen den verbundenen Autoren zu maximieren wird folgendes min
Problem(Equation 1) definiert. Lösung ist die Verwendung der Eigenvektoren der
zwei kleinsten Eigenwerte.
Um eine „Auffächerung“ zu erreichen wird die Y- Achse nach dem Verhältnis
dieser beiden Eigenwerte skaliert.
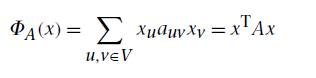
Equation 1:
Funktion des min Problems(Reprinted from
[BL])
Die
Berechnung erfolgt in der Klasse: CalcPosition
1.1.2
Autorendaten
Ob ein User als Autor oder als Lektor auftritt wird
mittels dem Verhältnis der eingehenden und ausgehenden Verbindungen bestimmt.
Die Darstellung erfolgt über das x y Verhältnis der Knotenellipse.
Die Linienstärke ergibt sich aus dem Gesamtgewicht der Verbindung zwischen zwei
Usern. Die Darstellung ist abhängig davon, ob
die Korrekturabfolge gleichmäßig verläuft, oder ob ein User den anderen
signifikant öfter verbessert.
Die
Berechnungen erfolgen in der Klassen: CalcPosition, CalcStatistics
1.1.3
Filter
Um die Daten besser strukturieren zu können, bzw.
Zusammenhangskomponenten zu finden, wird Spectral Clustering verwendet.
Umsetzung ist in der Klasse: SpectralClusterProzessor zu finden(Aufruf durch
FilterCluster)
1.4
Graphical User
Interface(GUI)
Die
Webseite ist mittels JSP und d3js (http://http://d3js.org/)
umgesetzt.
Die
Daten werden vom JSON-Webservice abgerufen,
die Änderungshäufigkeit als
Bar-Chart und die Userzusammenhänge in
der
vom Paper vorgeschlagen Form dargestellt.
Im Feld Site wird die ID der Wiki Seite eingegeben. Mit
dem Start-Button werden die Daten abgerufen und aufbereitet.
Mit dem Slidebar können Verbindungen je nach Gewichtung ausgeblendet werden.
Wobei je Seite die Gewichte jeweils zwischen 0 und 1 normiert sind.
Mit der Checkbox Cluster wird
Spektral-Clustering aktiviert. Die Zahl neben der Checkbox definiert die
Clusteranzahl für den verwendeten Kmeans Algorithmus.
Die folgende Select-Box enthält die Auswahl der generierten Cluster. Mit dem
Start Button werden die Daten aktualisiert.
Der Zeitbereich kann mittels Mouse-Click auf den
jeweiligen Start und End-Bar eingeschränkt werden. Der Bereich wird mit einem
blauen Rechteck hinterlegt.
Sind die jeweiligen Knoten zu nahe, so werden für die
Darstellung der Knotennamen im Uhrzeigersinn(CW) gebündelt.
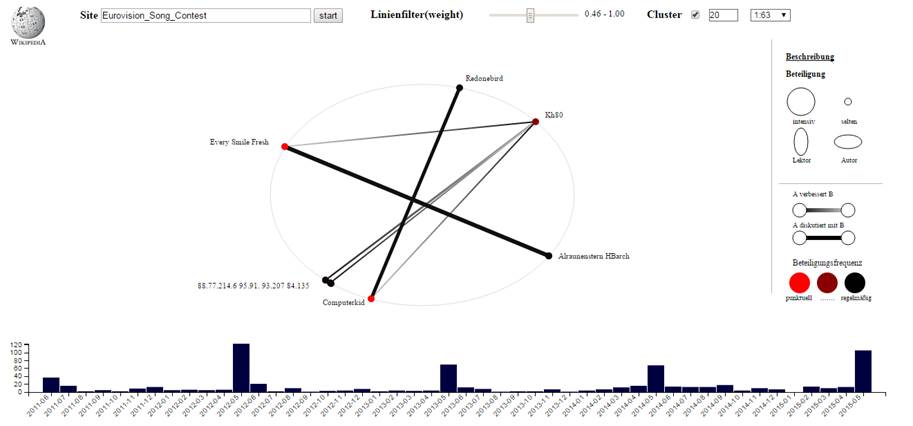
Bild 2 GUI
1.5
Programm
Das Programm ist als Java-Webanwendung umgesetzt.
Diese kann auf einen JSR-330 kompatiblen Web Container Server deployed werden. Für
die Implementierung wird Tomcat 8 verwendet.
Das System ist für Java 8 und Tomcat 8 konfiguriert.
Die Sourcen für das Web Container Projekt ist unter
folgendem Link zu finden.
Entwicklungsumgebung: Eclipse
Luna, Maven 3, Java 8,Tomcat 8 (weitere Versionen siehe maven pom File)
1.6
Dokumentation
Die Klassendokumentation ist
mit JavaDoc erstellt worden.
4 Literatur
[BL] U. Brandes and J. Lerner. Visual analysis of
controversy in user-generatedencyclopedias.
In IEEE
Symposium on Visual Analytics Science and Technology, pages
179-186,2007.