Paper description
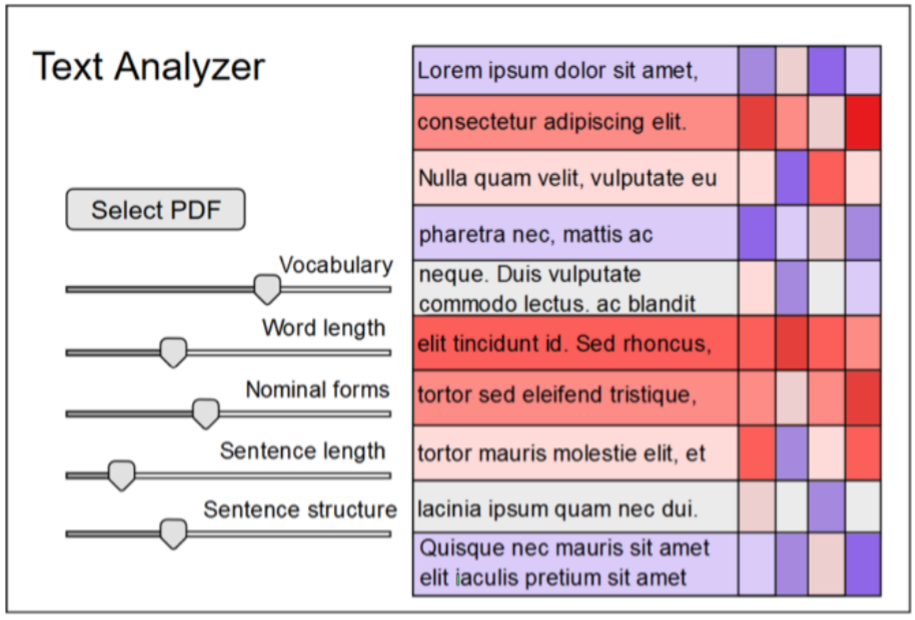
The paper by Oelke et al. [1] analyzes the readability in text documents. It shows which parts are easy to read, which parts are more difficult to read and especially why this is the case. The authors use a semi-automatic approach to select five readability measures out of 141 text- feature-candidates. They analyze the complexity of the vocabulary used in a document, by consulting a dictionary. Furthermore they take into account the sentence length and structure, the word length and the use of nominal forms. The longer a sentence or word is, the more sub-sentences it contains, or the more nominal forms occur, the more difficult it is to read. From these measure criteria, the authors calculate an overall score and visualize the result in three different views. The detail view analyzes each single sentence in term of readability, while the block view analyzes whole text blocks or sections. The corpus view gives an overview of all pages.
Task description
TextAnalyzer is a tool that analyzes the readability of PDF text-documents. The user selects a PDF file and weights each feature by updating sliders. The results are displayed as a detailed analysis in the user interface and as an annotated PDF file.
Implementation
TextAnalyzer is programmed with Python 3.7, 64 bit. First, the user selects a PDF file to analyze. Then the program extracts characters from the PDF file with PDfMiner. It defines the sentences from the extracted characters. Next, the system evaluates the readability of each sentence by computing six features. This features are the complexity of the vocabulary used, the word length, the nominal forms, the length of the sentence, the sentence structure, and the use of imprecise formulations.
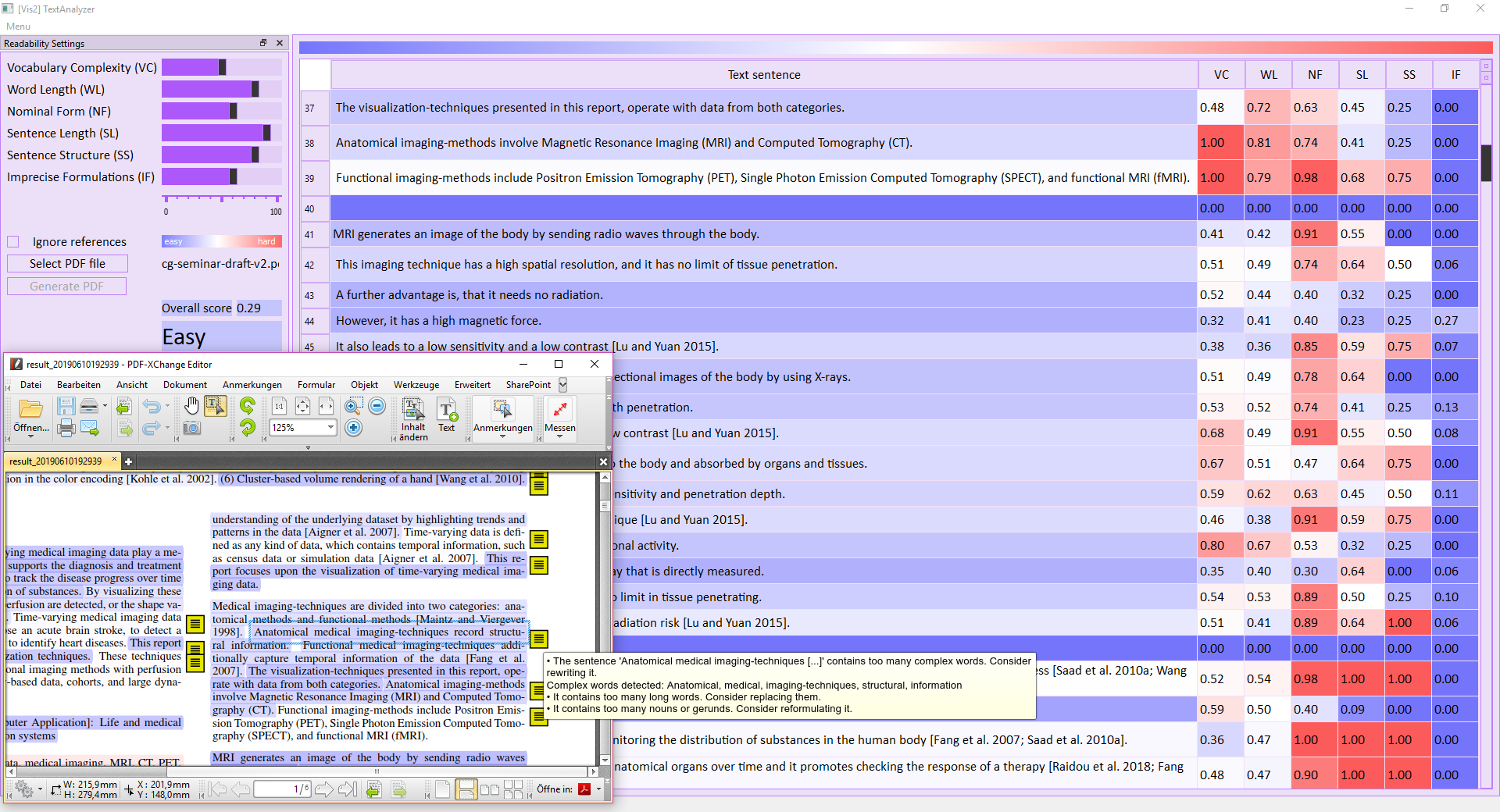
- Vocabulary complexity
The percentage of terms not contained in a list of the 1000 most frequent terms in english language. - Word length
The average number of characters in a word. - Nominal forms
The combination of the noun-to-verb ratio and the number of nominal forms. The number of verbs, nomens, and nominals is retrieved by NLTK. - Sentence length
The number of words in a sentence. - Sentence structure
The number of interruptions by sub-sentences or parenthesis. - Imprecise formulations
The percentage of terms contained in a list of imprecise formulations. This list is collected from different guidelines for writing papers or reports.
The system computes scores for each of the features, and for the whole sentence. Further, an overall score for the document is retrieved. From these scores, colors are interpolated. These colors are shown in the user interface and are used for highlighting the PDF files. The result is displayed in the user interface, programmed with PyQt5. The user has the possibility to adjust the weight of each feature by updating its sliders. This leads to a recalculation of the sentence score. Once this adjustment is finished, the user can generate a highlighted PDF file. This is done by PYMuPDF. In this PDF, more detailed comments are described that aim to help the user in improving the readability of the document. If the user wants to know, how an enhancement of a particular sentence effects the readability score, it is possible to directly edit sentences in the user interface. This leads to a recalculation of all feature scores, of the sentence score, and of the overall score. For more detail please go to module page and index page or see the pdf documentation.
Program controls
- Select PDF file:
Click on the button "Select PDF file" and select the file to analyze. After selecting the file, the sentences are extracted and analyzed. The resulting scores are visible in the user interface. Sentences are colored based on these scores. - Ignore references:
Check this box to ignore all references in the readability analysis.
- Gererate PDF:
The button "Generate PDF" creates and shows a highlighted and annotated pdf file. - Comments in PDF:
For all features that hit a certain limit for a sentence, a comment is displayed in the PDF. The comment denotes, which features hit this limit. Further, it gives an advise of how to improve the readability for the affected features. - Edit sentence:
Double click on a sentence in the user interface and update the text. This shows in realtime, how an improvement of the sentence will affect the readability scores. - Weight features:
By updating the sliders, the weight of every feature is set between 0 and 100%. This leads to an update of the sentence score.
- Features score:
For every feature, limits are defined. The features score is calculated by normalizing the value in the defined limits. - Sentence score:
The sentence score is calculated by taking the mean of feature scores of a sentence. Only scores that are weighted higher than 0 are considered in the calculation. - Overall score:
The overall score is calculated from all sentence scores. - Color meaning:
Colors are interpolated between blue, white, and red. Sentences marked in blue are easy to read. Sentences with a white highlight are neutral. Sentences with a red background are hard to read.





Reference
[1] Daniela Oelke, David Spretke, Andreas Stoffel, Daniel Keim. Visual readability analysis: How to make your writings easier to read. IEEE Visual Analytics Science and Technology (VAST), p. 123–130, 2010.