

Speaker: Lukas Machegger
Background: Glioblastoma multiforme (GBM) is the most aggressive form of brain cancer, characterized by rapid growth and infiltration into surrounding brain tissue. Precise segmentation of GBM, particularly the contrast-enhancing region and necrotic (non-contrast-enhaning) core, is critical for surgical planning and treatment. Manual segmentation methods are time-consuming and subject to high interrater variability, necessitating automated approaches for greater consistency.
Objective: This thesis aims to optimize key parameters in deep learning-based segmentation of glioblastomas, focusing on the impact of Batch size, data augmentation strategies, and the number of training cases on model performance, along with tuning the Focal Weight Factor in the Combined Loss Function. The goal is to improve the accuracy of segmenting clinically relevant tumor regions.
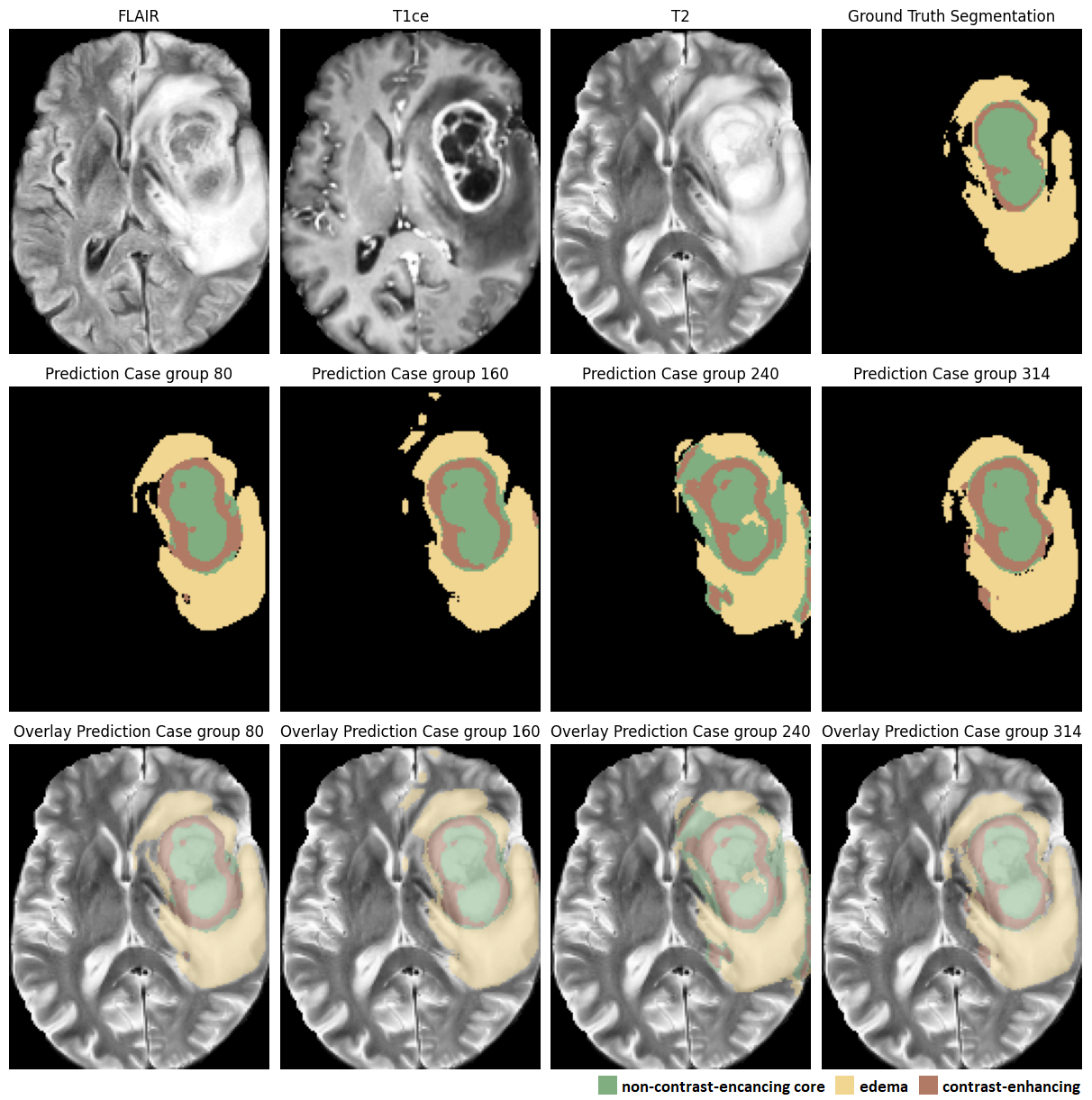
Methods: In this study, 3D U-Net models were trained using the BraTS Challenge dataset, which includes multimodal MRI scans (T1 post-contrast, FLAIR, and T2) with expert-labeled segmentations reviewed by a neuroradiologist to eliminate interrater variability. The models were evaluated on 108 unseen clinical cases from patients at the University Hospital Salzburg to assess their generalization capability and performance. Segmentation accuracy was measured using Intersection over Union (IoU) and a Custom Weighted Dice Score, focusing on Dice coefficients for the contrast-enhancing and non-contrast-enhancing tumor. Four Case Groups (80, 160, 240, and 314) were used to examine the effect of Case Group size on performance.
Results: Models trained with Batch size of four consistently ranked among the top performers, with 80% making it into the top 10, suggesting that larger Batch sizes contribute to better generalization and stability as number of training cases increase. However, augmentations generally resulted in worse performance, except for one outlier—the best performing model—trained with a 1:1 ratio of augmentations to originals, Case Group 314, and a Batch size of one, which performed exceptionally well.
Conclusion: Augmentations with a ratio of 1:3 performed poorly, particularly when three variants of one original were included in a Batch size of four, leading to overfitting. This suggests a lack of diversity within the batches caused the model to overfit, whereas a strategy mixing different augmentations within each batch led to better generalization. Case Group 314 models performed best, highlighting the importance of more training data for improved performance.
Details
Category
Duration
20 + 20
Supervisor: Eduard Gröller