

Markus Lipp, Peter Wonka , Michael Wimmer
, Michael Wimmer
Parallel Generation of Multiple L-Systems
Computers & Graphics, 34(5):585-593, October 2010. [ preprint]
preprint]
Information
- Publication Type: Journal Paper (without talk)
- Workgroup(s)/Project(s):
- Date: October 2010
- ISSN: 0097-8493
- Journal: Computers & Graphics
- Number: 5
- Volume: 34
- Pages: 585 – 593
Abstract
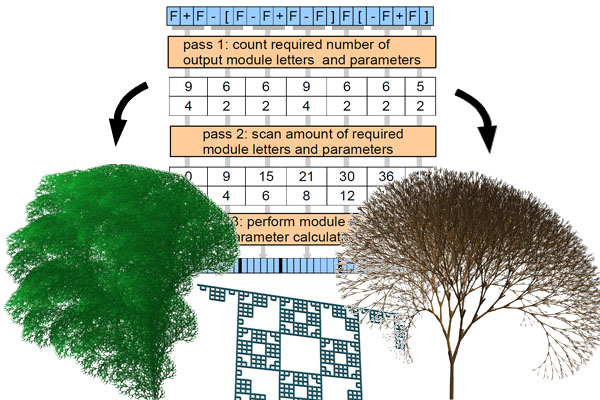
This paper introduces a solution to compute L-systems on parallel architectures like GPUs and multi-core CPUs. Our solution can split the derivation of the L-system as well as the interpretation and geometry generation into thousands of threads running in parallel. We introduce a highly parallel algorithm for L-system evaluation that works on arbitrary L-systems, including parametric productions, context sensitive productions, stochastic production selection, and productions with side effects. This algorithm is further extended to allow evaluation of multiple independent L-systems in parallel. In contrast to previous work, we directly interpret the productions defined in plain-text, without requiring any compilation or transformation step (e.g., into shaders). Our algorithm is efficient in the sense that it requires no explicit inter-thread communication or atomic operations, and is thus completely lock free.Additional Files and Images

Weblinks
No further information available.BibTeX
@article{LIPP-2010-PGMS,
title = "Parallel Generation of Multiple L-Systems",
author = "Markus Lipp and Peter Wonka and Michael Wimmer",
year = "2010",
abstract = "This paper introduces a solution to compute L-systems on
parallel architectures like GPUs and multi-core CPUs. Our
solution can split the derivation of the L-system as well as
the interpretation and geometry generation into thousands of
threads running in parallel. We introduce a highly parallel
algorithm for L-system evaluation that works on arbitrary
L-systems, including parametric productions, context
sensitive productions, stochastic production selection, and
productions with side effects. This algorithm is further
extended to allow evaluation of multiple independent
L-systems in parallel. In contrast to previous work, we
directly interpret the productions defined in plain-text,
without requiring any compilation or transformation step
(e.g., into shaders). Our algorithm is efficient in the
sense that it requires no explicit inter-thread
communication or atomic operations, and is thus completely
lock free.",
month = oct,
issn = "0097-8493",
journal = "Computers & Graphics",
number = "5",
volume = "34",
pages = "585--593",
URL = "https://www.cg.tuwien.ac.at/research/publications/2010/LIPP-2010-PGMS/",
}