

Thomas Weber
Micropolygon Rendering on the GPU
[![]() thesis]
thesis]
Information
- Publication Type: Master Thesis
- Workgroup(s)/Project(s):
- Date: January 2015
- Date (Start): 1. January 2013
- Date (End): 13. January 2015
- TU Wien Library:
- Diploma Examination: 13. January 2015
- First Supervisor: Michael Wimmer

Abstract
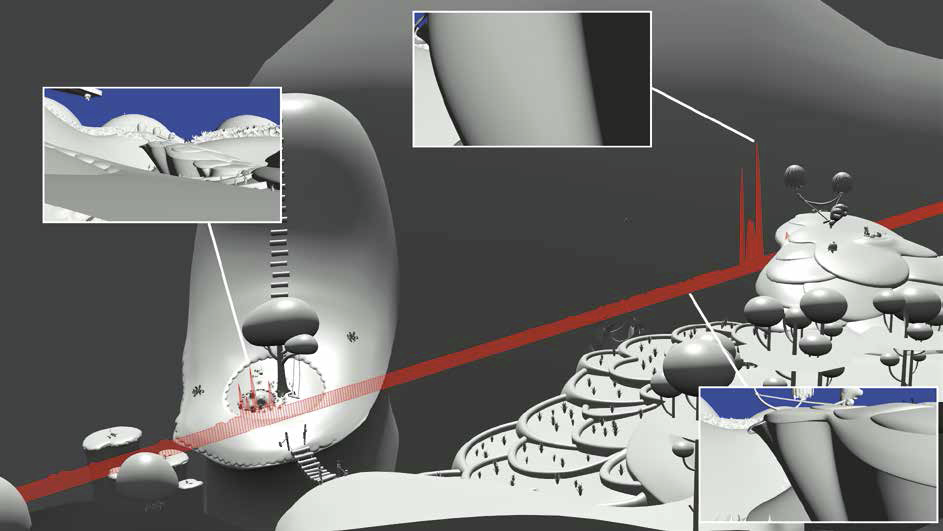
Recent advances in graphics hardware have made it a desirable goal to implement the Reyes algorithm commonly used in production rendering to run on current graphics cards. One key component in this algorithm is the bound-and-split phase, where surface patches are recursively split until they are smaller than a given screen-space bound. While this operation has been successfully parallelized for execution on the GPU using a breadth-first traversal, the resulting implementations are limited by their unpredictable worst-case memory consumption and high global memory bandwidth utilization. In this paper, we propose an alternate strategy that allows limiting the amount of necessary memory by controlling the number of assigned worker threads. The result is an implementation that scales to the performance of the breadth-first approach while offering three advantages: significantly decreased memory usage, a smooth and predictable tradeoff between memory usage and performance, and increased locality for surface processing. This allows us to render scenes that would require too much memory to be processed by the breadth-first method.Additional Files and Images
Weblinks
No further information available.BibTeX
@mastersthesis{WEBER-2015-PRA1,
title = "Micropolygon Rendering on the GPU",
author = "Thomas Weber",
year = "2015",
abstract = "Recent advances in graphics hardware have made it a
desirable goal to implement the Reyes algorithm commonly
used in production rendering to run on current graphics
cards. One key component in this algorithm is the
bound-and-split phase, where surface patches are recursively
split until they are smaller than a given screen-space
bound. While this operation has been successfully
parallelized for execution on the GPU using a breadth-first
traversal, the resulting implementations are limited by
their unpredictable worst-case memory consumption and high
global memory bandwidth utilization. In this paper, we
propose an alternate strategy that allows limiting the
amount of necessary memory by controlling the number of
assigned worker threads. The result is an implementation
that scales to the performance of the breadth-first approach
while offering three advantages: significantly decreased
memory usage, a smooth and predictable tradeoff between
memory usage and performance, and increased locality for
surface processing. This allows us to render scenes that
would require too much memory to be processed by the
breadth-first method.",
month = jan,
address = "Favoritenstrasse 9-11/E193-02, A-1040 Vienna, Austria",
school = "Institute of Computer Graphics and Algorithms, Vienna
University of Technology ",
URL = "https://www.cg.tuwien.ac.at/research/publications/2015/WEBER-2015-PRA1/",
}