

Alexey Karimov, Gabriel Mistelbauer, Thomas Auzinger , Eduard Gröller
, Eduard Gröller
Statistics-Driven Localization of Dissimilarities in Data
TR-186-2-16-1, April 2016
Information
- Publication Type: Technical Report
- Workgroup(s)/Project(s):
- Date: April 2016
- Number: TR-186-2-16-1
Abstract
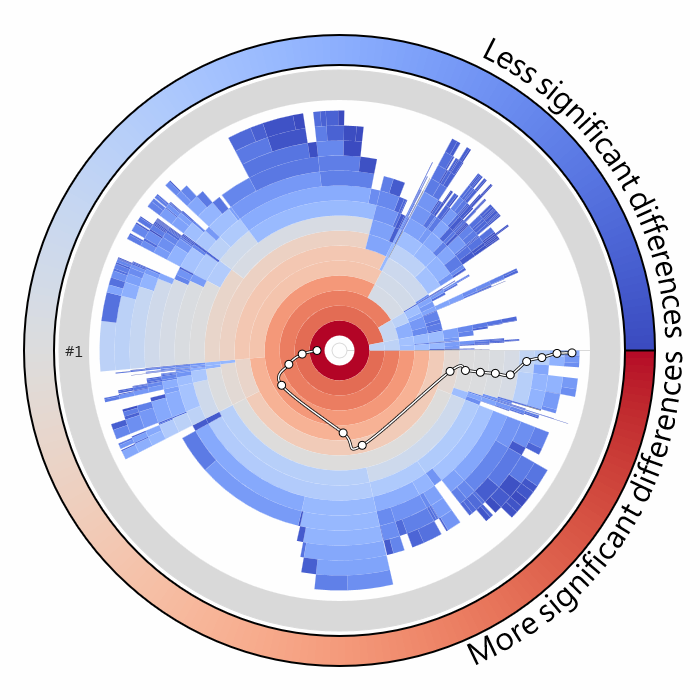
The identification of dissimilar regions in spatial and temporal data is a fundamental part of data exploration. This process takes place in applications, such as biomedical image processing as well as climatic data analysis. We propose a general solution for this task by employing well-founded statistical tools. From a large set of candidate regions, we derive an empirical distribution of the data and perform statistical hypothesis testing to obtain p-values as measures of dissimilarity. Having p-values, we quantify differences and rank regions on a global scale according to their dissimilarity to user-specified exemplar regions. We demonstrate our approach and its generality with two application scenarios, namely interactive exploration of climatic data and segmentation editing in the medical domain. In both cases our data exploration protocol unifies the interactive data analysis, guiding the user towards regions with the most relevant dissimilarity characteristics. The dissimilarity analysis results are conveyed with a radial tree, which prevents the user from searching exhaustively through all the data.Additional Files and Images
Weblinks
No further information available.BibTeX
@techreport{karimov-2016-SD,
title = "Statistics-Driven Localization of Dissimilarities in Data",
author = "Alexey Karimov and Gabriel Mistelbauer and Thomas Auzinger
and Eduard Gr\"{o}ller",
year = "2016",
abstract = "The identification of dissimilar regions in spatial and
temporal data is a fundamental part of data exploration.
This process takes place in applications, such as biomedical
image processing as well as climatic data analysis. We
propose a general solution for this task by employing
well-founded statistical tools. From a large set of
candidate regions, we derive an empirical distribution of
the data and perform statistical hypothesis testing to
obtain p-values as measures of dissimilarity. Having
p-values, we quantify differences and rank regions on a
global scale according to their dissimilarity to
user-specified exemplar regions. We demonstrate our approach
and its generality with two application scenarios, namely
interactive exploration of climatic data and segmentation
editing in the medical domain. In both cases our data
exploration protocol unifies the interactive data analysis,
guiding the user towards regions with the most relevant
dissimilarity characteristics. The dissimilarity analysis
results are conveyed with a radial tree, which prevents the
user from searching exhaustively through all the data.",
month = apr,
number = "TR-186-2-16-1",
address = "Favoritenstrasse 9-11/E193-02, A-1040 Vienna, Austria",
institution = "Institute of Computer Graphics and Algorithms, Vienna
University of Technology ",
note = "human contact: technical-report@cg.tuwien.ac.at",
URL = "https://www.cg.tuwien.ac.at/research/publications/2016/karimov-2016-SD/",
}