

Muhammad Samoul
Visual Comparison of NLP Pipelines
Information
- Publication Type: Student Project
- Workgroup(s)/Project(s):
- Date: 2019
- Date (Start): November 2018
- Date (End): April 2019
- Matrikelnummer: 11833154
- First Supervisor: Manuela Waldner

Abstract
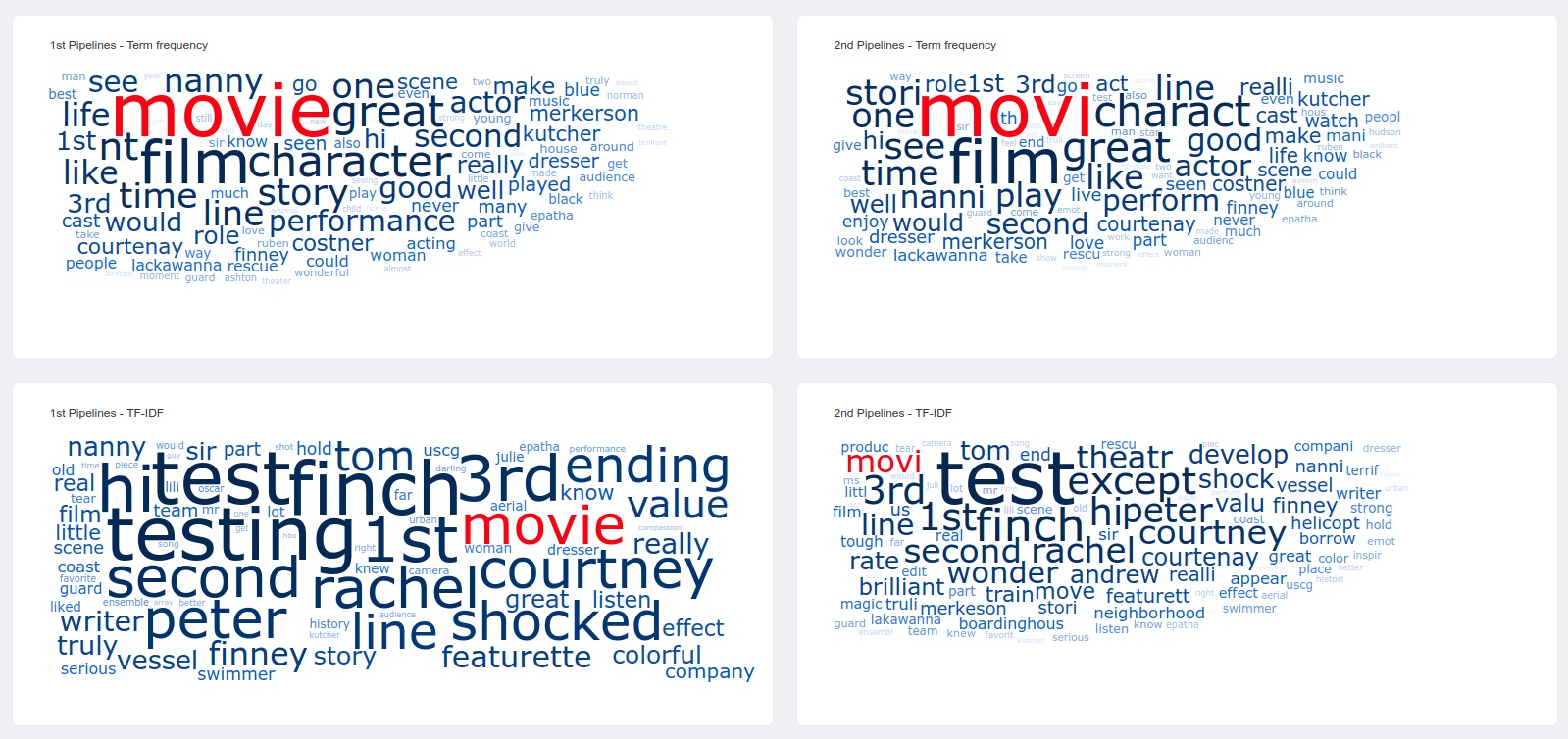
Natural Language Processing (NLP) is a sub-field of artificial intelligence (AI). It enables computers to understand, process and analyze large amounts of unstructured natural language data (raw text). Nowadays with the new techniques of machine learning, we got good performance and brings us closer to unfolding the semantic meaning of the text. However, it is far from perfect. Therefore, an alternative approach to helping humans understand a text corpus is to provide a visualization of the content. To generate such a visualization, several NLP steps are necessary to convert the raw text into features, such as weighted keywords or phrases, that can be visualized. The words to be visualized and their weights strongly depend on which NLP steps are performed, in which order, and with which parameters. However, there is currently no standard how to set up such an NLP pipeline and NLP pipeline configurations vary significantly across visualizations and input texts. Our project consists of visualizing high dimensional data with different pre-processing steps with a different order. To compare the results, we choose a well-known and wide-spread overview visualization technique: word clouds. Word clouds are composed of words used in a particular text or subject, in which the size of each word indicates its weight computed in the course of the NLP pipeline.Additional Files and Images

Weblinks
No further information available.BibTeX
@studentproject{samoul-2019-cnp,
title = "Visual Comparison of NLP Pipelines",
author = "Muhammad Samoul",
year = "2019",
abstract = "Natural Language Processing (NLP) is a sub-field of
artificial intelligence (AI). It enables computers to
understand, process and analyze large amounts of
unstructured natural language data (raw text). Nowadays with
the new techniques of machine learning, we got good
performance and brings us closer to unfolding the semantic
meaning of the text. However, it is far from perfect.
Therefore, an alternative approach to helping humans
understand a text corpus is to provide a visualization of
the content. To generate such a visualization, several NLP
steps are necessary to convert the raw text into features,
such as weighted keywords or phrases, that can be
visualized. The words to be visualized and their weights
strongly depend on which NLP steps are performed, in which
order, and with which parameters. However, there is
currently no standard how to set up such an NLP pipeline and
NLP pipeline configurations vary significantly across
visualizations and input texts. Our project consists of
visualizing high dimensional data with different
pre-processing steps with a different order. To compare the
results, we choose a well-known and wide-spread overview
visualization technique: word clouds. Word clouds are
composed of words used in a particular text or subject, in
which the size of each word indicates its weight computed in
the course of the NLP pipeline.",
month = apr,
URL = "https://www.cg.tuwien.ac.at/research/publications/2019/samoul-2019-cnp/",
}