

Adam Celarek, Pedro Hermosilla-Casajus , Bernhard Kerbl, Timo Ropinski, Michael Wimmer
, Bernhard Kerbl, Timo Ropinski, Michael Wimmer
Gaussian Mixture Convolution Networks
In The Tenth International Conference on Learning Representations (ICLR 2022), pages 1-23. April 2022.
[ paper] [Code on github]
paper] [Code on github]
Information
- Publication Type: Conference Paper
- Workgroup(s)/Project(s):
- Date: April 2022
- Publisher: OpenReview.org
- Open Access: yes
- Lecturer: Adam Celarek
- Event: ICLR | 2022
- Call for Papers: Call for Paper
- Booktitle: The Tenth International Conference on Learning Representations (ICLR 2022)
- Pages: 1 – 23
Abstract
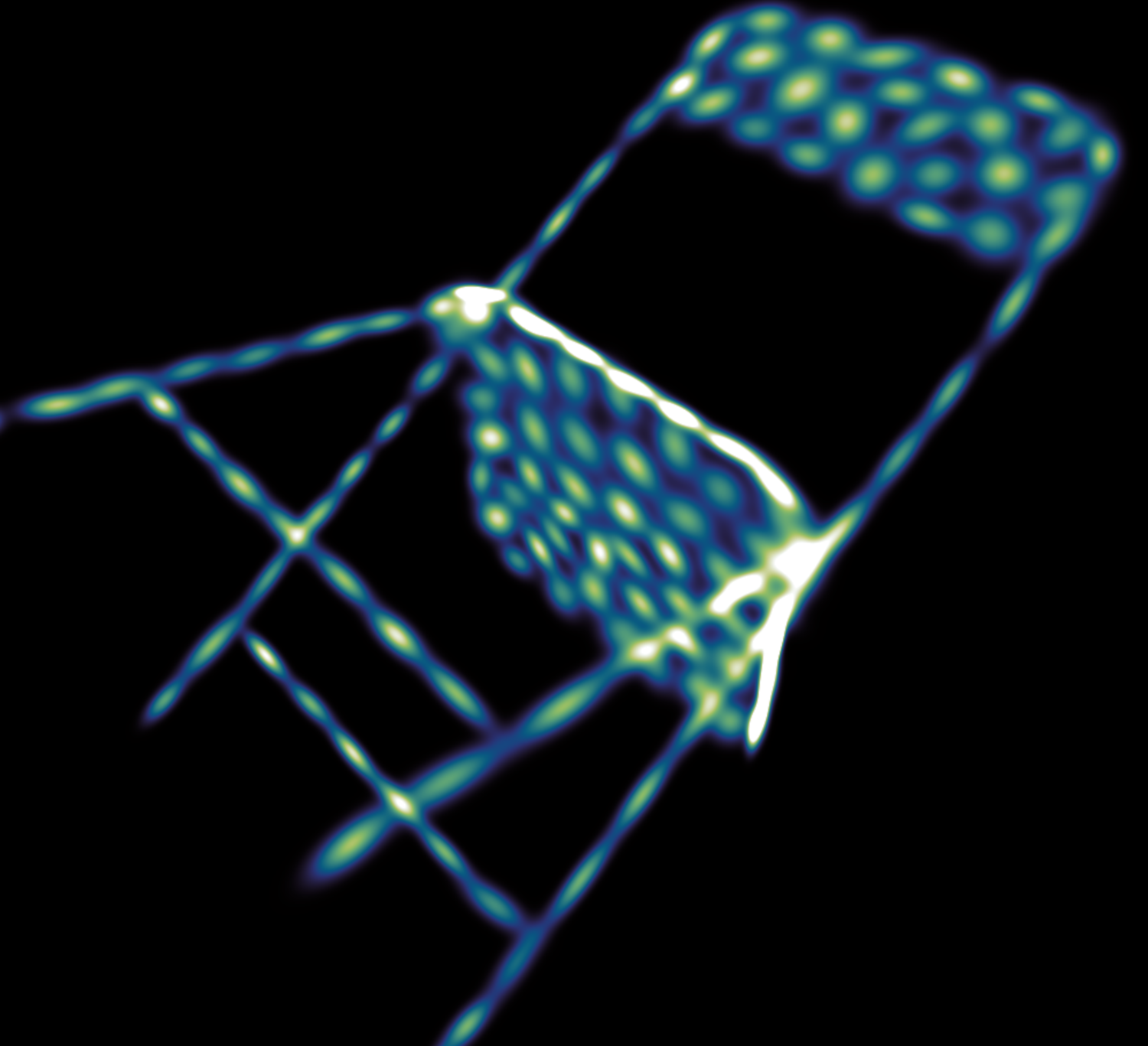
This paper proposes a novel method for deep learning based on the analytical convolution of multidimensional Gaussian mixtures. In contrast to tensors, these do not suffer from the curse of dimensionality and allow for a compact representation, as data is only stored where details exist. Convolution kernels and data are Gaussian mixtures with unconstrained weights, positions, and covariance matrices. Similar to discrete convolutional networks, each convolution step produces several feature channels, represented by independent Gaussian mixtures. Since traditional transfer functions like ReLUs do not produce Gaussian mixtures, we propose using a fitting of these functions instead. This fitting step also acts as a pooling layer if the number of Gaussian components is reduced appropriately. We demonstrate that networks based on this architecture reach competitive accuracy on Gaussian mixtures fitted to the MNIST and ModelNet data sets.Additional Files and Images

Weblinks
BibTeX
@inproceedings{celarek-2022-gmcn,
title = "Gaussian Mixture Convolution Networks",
author = "Adam Celarek and Pedro Hermosilla-Casajus and Bernhard Kerbl
and Timo Ropinski and Michael Wimmer",
year = "2022",
abstract = "This paper proposes a novel method for deep learning based
on the analytical convolution of multidimensional Gaussian
mixtures. In contrast to tensors, these do not suffer from
the curse of dimensionality and allow for a compact
representation, as data is only stored where details exist.
Convolution kernels and data are Gaussian mixtures with
unconstrained weights, positions, and covariance matrices.
Similar to discrete convolutional networks, each convolution
step produces several feature channels, represented by
independent Gaussian mixtures. Since traditional transfer
functions like ReLUs do not produce Gaussian mixtures, we
propose using a fitting of these functions instead. This
fitting step also acts as a pooling layer if the number of
Gaussian components is reduced appropriately. We demonstrate
that networks based on this architecture reach competitive
accuracy on Gaussian mixtures fitted to the MNIST and
ModelNet data sets.",
month = apr,
publisher = "OpenReview.org",
event = "ICLR | 2022",
booktitle = "The Tenth International Conference on Learning
Representations (ICLR 2022)",
pages = "1--23",
URL = "https://www.cg.tuwien.ac.at/research/publications/2022/celarek-2022-gmcn/",
}