

Bernhard Kerbl , Michael Kenzel, Martin Winter, Markus Steinberger
, Michael Kenzel, Martin Winter, Markus Steinberger
CUDA and Applications to Task-based Programming
In Eurographics 2022 - Tutorials. April 2022.
[ paper]
paper]
Information
- Publication Type: Other Reviewed Publication
- Workgroup(s)/Project(s):
- Date: 2022
- Booktitle: Eurographics 2022 - Tutorials
- Editor: Stefanie Hahmann and Gustavo Patow
- Location: Reims
- Publisher: The Eurographics Association
- Keywords: Parallel Programming, GPU
Abstract
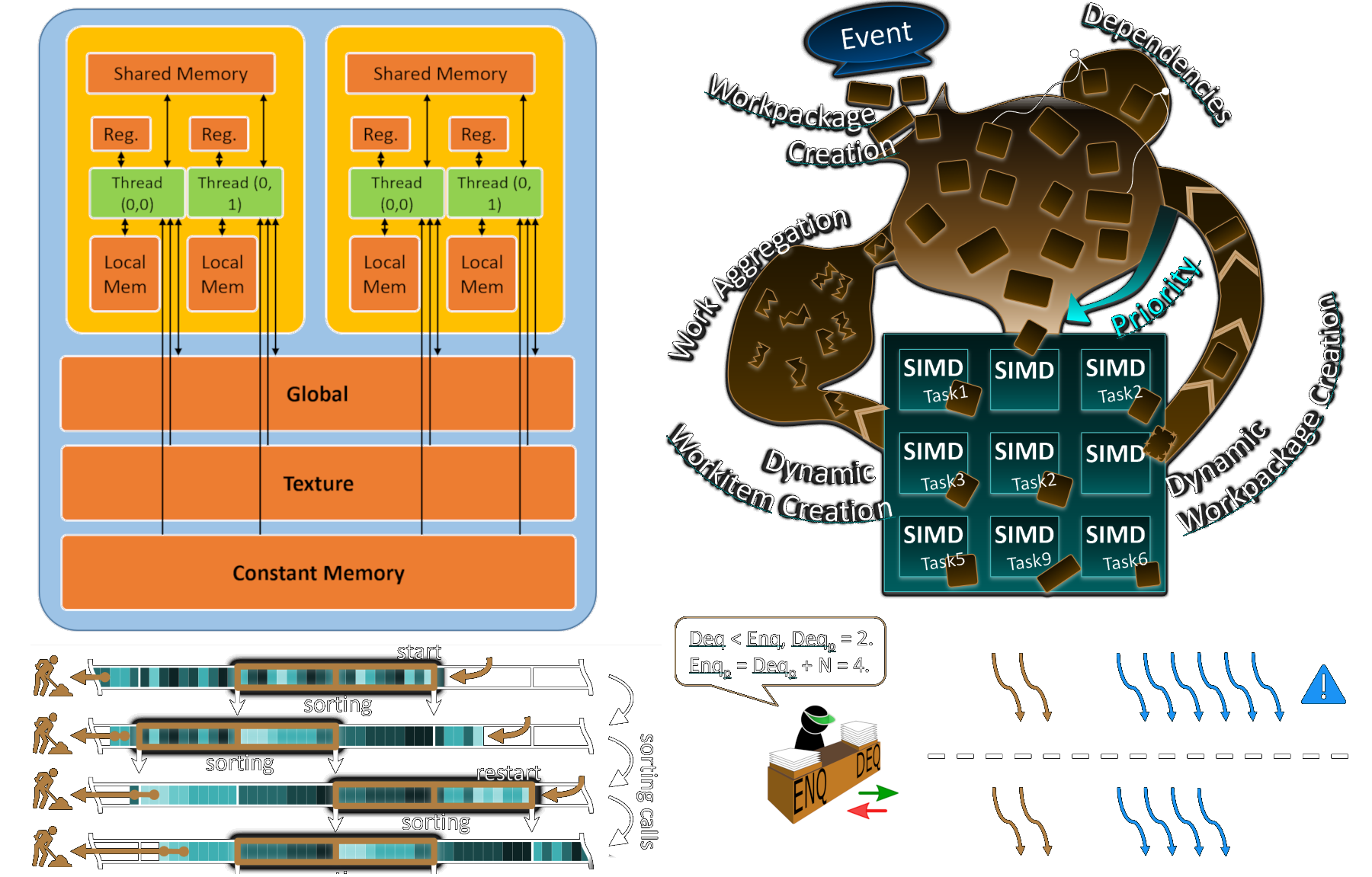
To provide a profound understanding of how CUDA applications can achieve peak performance, the first two parts of this tutorial outline the modern CUDA architecture. Following a basic introduction, we expose how language features are linked to---and constrained by---the underlying physical hardware components. Furthermore, we describe common applications for massively parallel programming, offer a detailed breakdown of potential issues, and list ways to mitigate performance impacts. An exemplary analysis of PTX and SASS snippets illustrates how code patterns in CUDA are mapped to actual hardware instructions.In parts 3 and 4, we focus on novel features that were enabled by the arrival of CUDA 10+ toolkits and the Volta+ architectures, such as ITS, tensor cores, and the graph API. In addition to basic use case demonstrations, we outline our own experiences with these capabilities and their potential performance benefits. We also discuss how long-standing best practices are affected by these changes and describe common caveats for dealing with legacy code on recent GPU models. We show how these considerations can be implemented in practice by presenting state-of-the-art research into task-based GPU scheduling, and how the dynamic adjustment of thread roles and group configurations can significantly increase performance.
Additional Files and Images

Weblinks
- Tutorial Homepage
Course notes and code samples for the tutorial
BibTeX
@inproceedings{kerbl-2022-cuda,
title = "CUDA and Applications to Task-based Programming",
author = "Bernhard Kerbl and Michael Kenzel and Martin Winter and
Markus Steinberger",
year = "2022",
abstract = "To provide a profound understanding of how CUDA applications
can achieve peak performance, the first two parts of this
tutorial outline the modern CUDA architecture. Following a
basic introduction, we expose how language features are
linked to---and constrained by---the underlying physical
hardware components. Furthermore, we describe common
applications for massively parallel programming, offer a
detailed breakdown of potential issues, and list ways to
mitigate performance impacts. An exemplary analysis of PTX
and SASS snippets illustrates how code patterns in CUDA are
mapped to actual hardware instructions. In parts 3 and 4,
we focus on novel features that were enabled by the arrival
of CUDA 10+ toolkits and the Volta+ architectures, such as
ITS, tensor cores, and the graph API. In addition to basic
use case demonstrations, we outline our own experiences with
these capabilities and their potential performance benefits.
We also discuss how long-standing best practices are
affected by these changes and describe common caveats for
dealing with legacy code on recent GPU models. We show how
these considerations can be implemented in practice by
presenting state-of-the-art research into task-based GPU
scheduling, and how the dynamic adjustment of thread roles
and group configurations can significantly increase
performance.",
month = apr,
booktitle = "Eurographics 2022 - Tutorials",
editor = "Stefanie Hahmann and Gustavo Patow",
location = "Reims",
publisher = "The Eurographics Association",
keywords = "Parallel Programming, GPU",
URL = "https://www.cg.tuwien.ac.at/research/publications/2022/kerbl-2022-cuda/",
}